
今、IoT(モノのインターネット)機器によってビッグデータ(大量のデジタルデータ)が集まり、AI(人工知能)によって新たな価値が生み出されています。これらの技術によって社会はより良い方向へ変化していくでしょう。このような状況を鑑み、松谷研はIoT、ビッグデータ、AIのための基盤技術(とくに計算機やアルゴリズム)を研究しています。
具体的には下記のプロジェクトに取り組んでいます。
- 深層ニューラルネットワークの軽量ファインチューニング
- エッジで学習可能なオンデバイス学習
- 移動ロボット向け自己位置推定および地図作成の高効率化
- 常微分方程式を基にした高効率ニューラルネットワーク
- 次世代無線ネットワークに向けた分散機械学習
- 高速インネットワーク機械学習・データ解析
- ビッグデータ処理の高性能化
- ビッグデータ蓄積検索の高性能化
- 光ビームを用いたデータセンターネットワーク
- チップ間無線を用いた3次元メニーコアプロセッサ
もう少し詳しい説明はここにあります。論文リストはここにあります。
深層ニューラルネットワークの軽量ファインチューニング(2023年〜)
深層ニューラルネットワーク(DNN)は画像認識に加え、言語モデルや生成モデルなど先端的なAIで広く使われています。今後、このようなタスクを計算資源の限られたエッジデバイスで動かすニーズも増えてくるでしょう。エッジAIにおいては、事前学習モデルと実際に配置される環境の間のズレが問題になりがちで、そのようなギャップを埋めるために置かれた現場でモデルをファインチューニングする技術が求められます。松谷研では計算機資源の限られたエッジデバイス上で動作する軽量ファインチューニング技術を研究しています(下図)。例えば、15ドルのシングルボード計算機でDNNのファインチューニングが数秒でできます。

※本研究は、情報工学科近藤研究室と共同で進めています。米国のテキサス大学オースティン校と共同研究を行っています。
※本研究の一部は、JST戦略的創造研究推進事業AIP加速課題のご支援を受けています(2023年4月から)。
エッジで学習可能なオンデバイス学習(2017年〜)
工場、倉庫、オフィス、家庭、屋外など実環境における異常検知を研究しています。実世界ではノイズや他の装置の稼働状況など外的要因によってセンサの値の見え方が変わってしまいます。「正解」がズレてしまうのです。松谷研では置かれたその場で正常を学習し、異常検知できる技術を研究しています。具体的には、身の回りに埋め込まれて動作するような小さくて軽いデバイス上で学習する技術「オンデバイス学習」を提案しています。4ドルのコントローラでも学習できます(下図)。仕組みは講演動画や解説記事で解説しています。
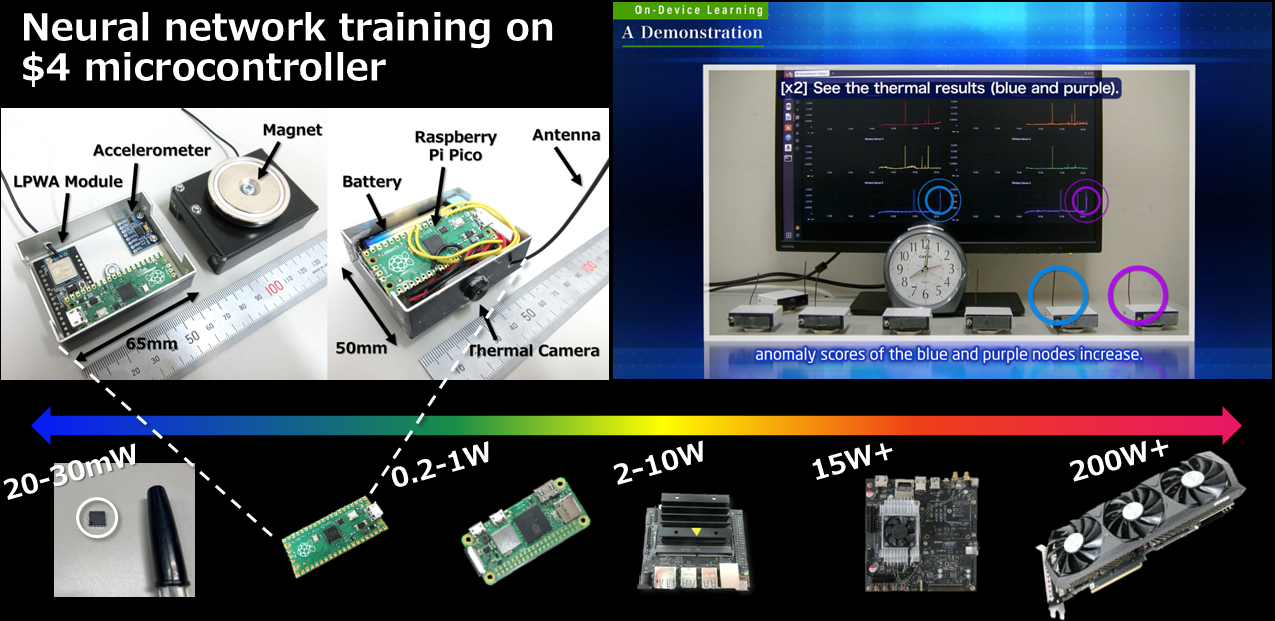
下記はオンデバイス学習のデモ動画です。いろいろな企業と協力して実証実験を行っています。例えば、オンデバイス学習のチップ化なども行っています。
※本研究は、情報工学科近藤研究室と共同で進めています。米国のテキサス大学オースティン校と共同研究を行っています。
※本研究の一部は、JST戦略的創造研究推進事業CRESTのご支援を受けました(2017年10月から2023年3月)。また、同AIP加速課題のご支援を受けています(2023年4月から)。
移動ロボット向け自己位置推定および地図作成の高効率化(2019年〜)
お掃除ロボットなど自律的に移動するロボットでは、壁や障害物がどこに有って、自分が今どこに居るのかを自律的に判断できなければなりません。このような自己位置推定および地図作成のためにSLAMという手法が使われます。
松谷研では、小さくてバッテリー容量に制限があるような移動ロボットを対象にSLAMアクセラレータを研究しています。
下記は小さなFPGA(再構成可能ハードウェア)ボード上で、2種類のSLAMを動かしたときのデモ動画です。大きくて高価なFPGAではなくて、小さくて安価なFPGA上で動かしているところが自慢です。
また、移動ロボット向けに、深層学習を使った点群レジストレーションや同じく深層学習を使った経路計画なども研究しています。下記は点群レジストレーションの高速化の例です。
常微分方程式を基にした高効率ニューラルネットワーク(2020年〜)
松谷研では、FPGAなどの小規模エッジデバイス対象に、パラメータ数が少なくて精度が高い畳み込みニューラルネットワークの推論器を研究しています。常微分方程式を基にしたニューラルネットワーク(Neural ODE)が提案されており、松谷研ではこれを基に高効率ネットワークを作ったり、小規模FPGA上で動作させたりしました。
最近では、Transformerと呼ばれる深層学習モデルが注目を浴びていますが、Neural ODEの考え方を応用してFPGA向けTiny Transformerモデルを作っています。下記はそのデモ動画です。
次世代無線ネットワークに向けた分散機械学習(2021年〜)
次世代の大容量、低遅延、多数同時接続可能な無線ネットワークの普及によって、今後は、物理空間とサイバー空間で情報をやり取りするコストが劇的に下がり、より豊かで便利なサービスの創出が期待されます。
こうした流れを見据えて、松谷研ではネットワークを介した分散機械学習を研究しています。具体的には、いろいろな制御に応用できる分散深層強化学習(ゲーム応用例)、エッジ端末同士で協力して学習する連合学習、エッジ-クラウド協調型のSLAMなどです。例えば、エッジ側でロボットなどが動き、クラウド側でモデルを学習するような分散深層強化学習を研究しています(下図)。
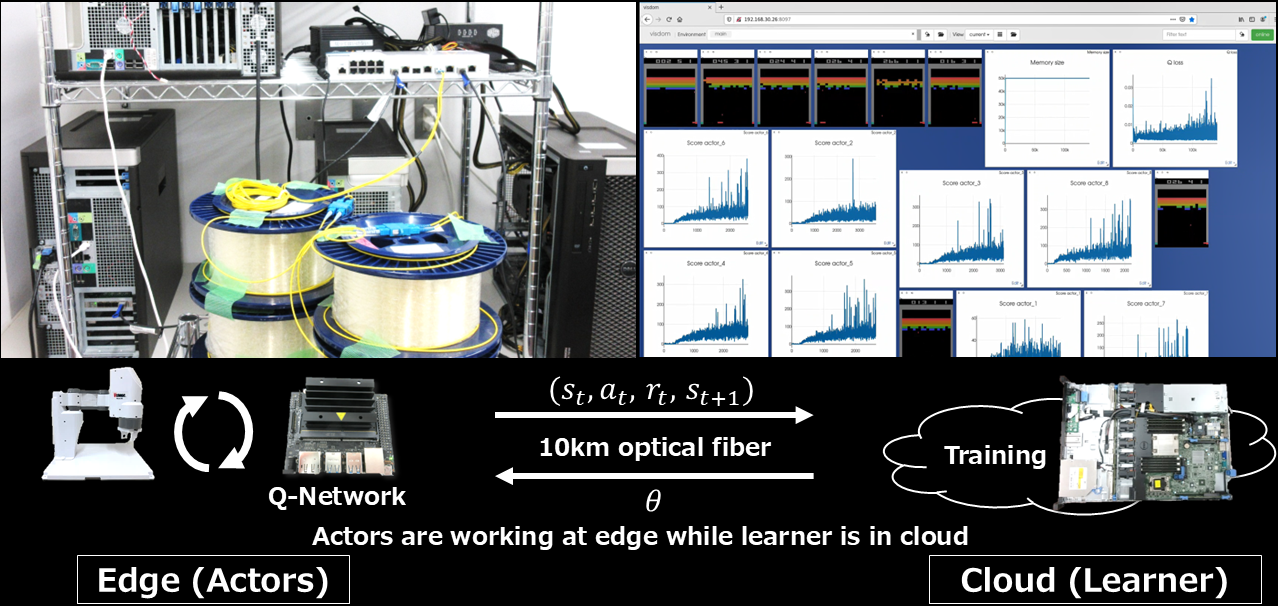
高速インネットワーク機械学習・データ解析(2014年〜2021年)
大量のデータ(ビッグデータ)の中から有益な情報を抽出すべく、ネットワークパケットに対する高速機械学習アルゴリズムを研究しました。例えば、10ギガビットイーサネットを備えたネットワークインタフェースカード上に機械学習アルゴリズムを実現し、大量のセンサデータの中から外れ値(不審者など)、変化点(株価の傾向の変化など)、異常行動(自動車の危険運転など)を検出できるようにしました。このようなインネットワーク機械学習技術を深層学習に応用しました。例えば、複数のGPU(グラフィックス処理ユニット)で計算した勾配の集約、重みパラメータの最適化(SGD、AdaGrad、Adam、SMORMS3アルゴリズムなど)の高速化を行いました。
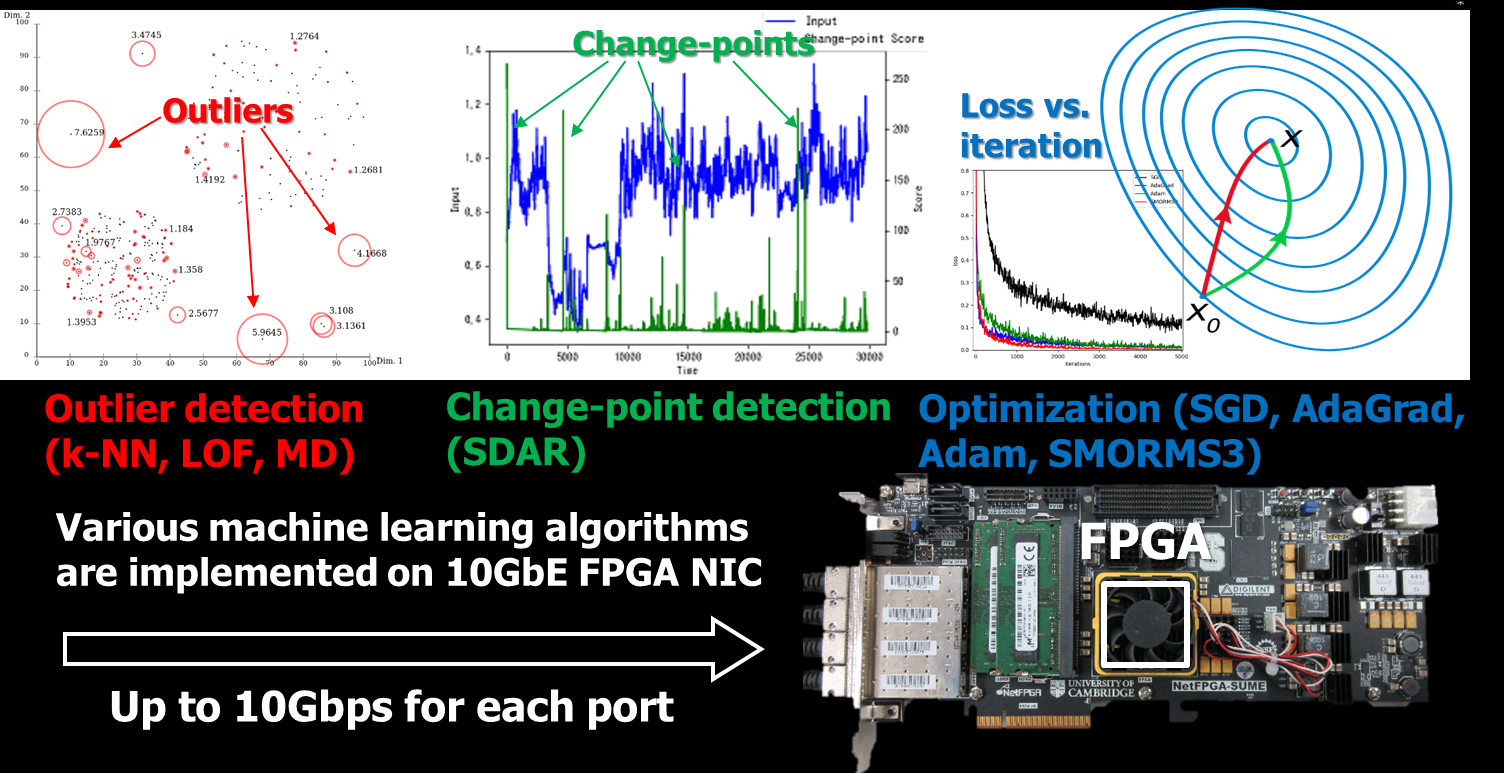
※本研究の一部は、JST戦略的創造研究推進事業さきがけのご支援を受けました(2013年10月から2017年3月)。
ビッグデータ処理の高性能化(2014年〜2019年)
現実空間もしくはネットワークサービスから集まる大量のデジタルデータを蓄積および解析し、その傾向をつかむことで、ビジネスの意思決定、流行の予測、犯罪防止、道路交通状況判断などに応用できると期待されています。
ビッグデータを利活用するには、いろいろな機能(ソフトウェア部品)が必要です(下図)。例えば、ストリームデータを集める機能、集めたストリームデータを逐次的に処理する機能、貯めてから一括処理する機能、データを蓄積検索する機能などです。この辺については解説記事を書いています。
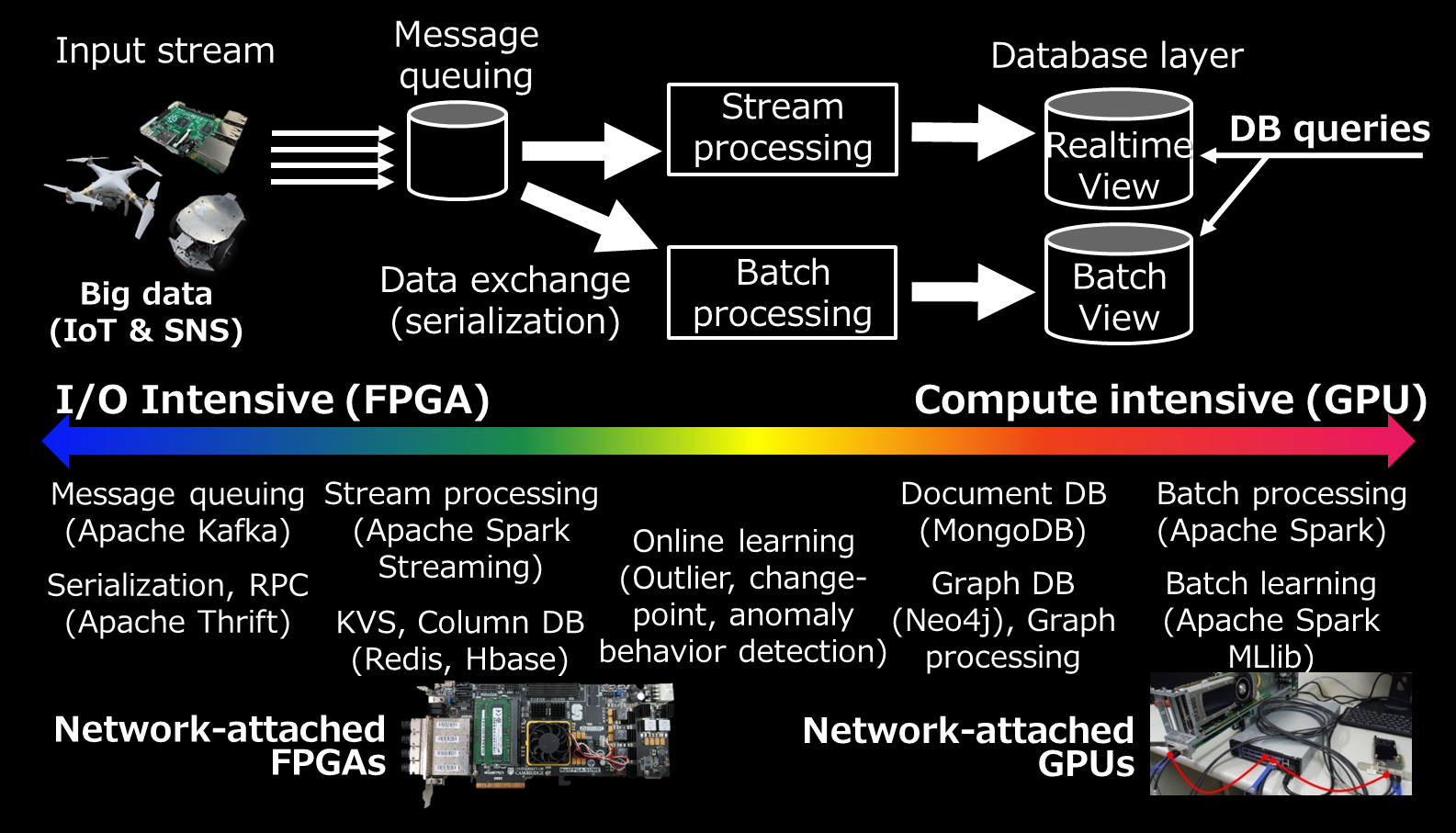
松谷研ではこれらのソフトウェア部品をFPGA(再構成可能ハードウェア)やGPU(グラフィックス処理ユニット)といったアクセラレータを使って高性能化しました。具体的には、10ギガビットイーサネットに接続された「ネットワーク接続型FPGA」、および、10ギガビットもしくは40ギガビットイーサネットに接続された「ネットワーク接続型GPU」を複数用いてHadoop、Spark、Spark Streamingなどのデータ処理フレームワークを高速化しました。
下記のように、ネットワーク接続型GPUを応用してGPUを持たないパソコンがネットワーク越しにあるGPUを使ってVR(Virtual Reality)を利用できるようにしたこともあります。
※本研究の一部は、JST戦略的創造研究推進事業さきがけのご支援を受けました(2013年10月から2017年3月)。
ビッグデータ蓄積検索の高性能化(2013年〜2019年)
ビッグデータの蓄積および検索のために、従来のリレーショナルデータベースに加えて、分散型のデータストア(NoSQL)の利用が注目されています。松谷研では10ギガビットイーサネットに接続された「ネットワーク接続型FPGA」、および、10ギガビットもしくは40ギガビットイーサネットに接続された「ネットワーク接続型GPU」を用いて様々なタイプのNoSQLを高性能化しました。例えば、下記ではネットワーク接続型FPGAを用いてキーバリュー型ストアを高速化しています。
他にもネットワーク接続型GPUを用いてドキュメント指向型ストアやグラフ指向型ストアを高速化しました。仮想通貨として注目を浴びているビットコイン(ブロックチェーン)を格納するためのデータストアを対象とした研究も行いました。
※本研究の一部は、JST戦略的創造研究推進事業さきがけのご支援を受けました(2013年10月から2017年3月)。
光ビームを用いたデータセンターネットワーク(2012年〜2018年)
松谷研では、サーバラックの上にコリメータレンズを設置し、このレンズを使って光信号を送受信することでサーバラック間を40Gbpsの光ビームで通信できるようにしました。レンズの向きを変えれば任意のサーバラック間に40Gbpsリンクを必要に応じて形成できます。我々はこれを「40Gbpsハイウェイ」と呼び、仮想マシンやビッグデータの移送に利用しました。下記は仮想マシンの移送の例です。
※本研究は、国立情報学研究所鯉渕研究室と共同で進めました。
※本研究の一部は、総務省 戦略的情報通信研究開発推進事業(SCOPE)のご支援を受けました(2013年4月から2014年3月、2016年4月から2018年3月)。
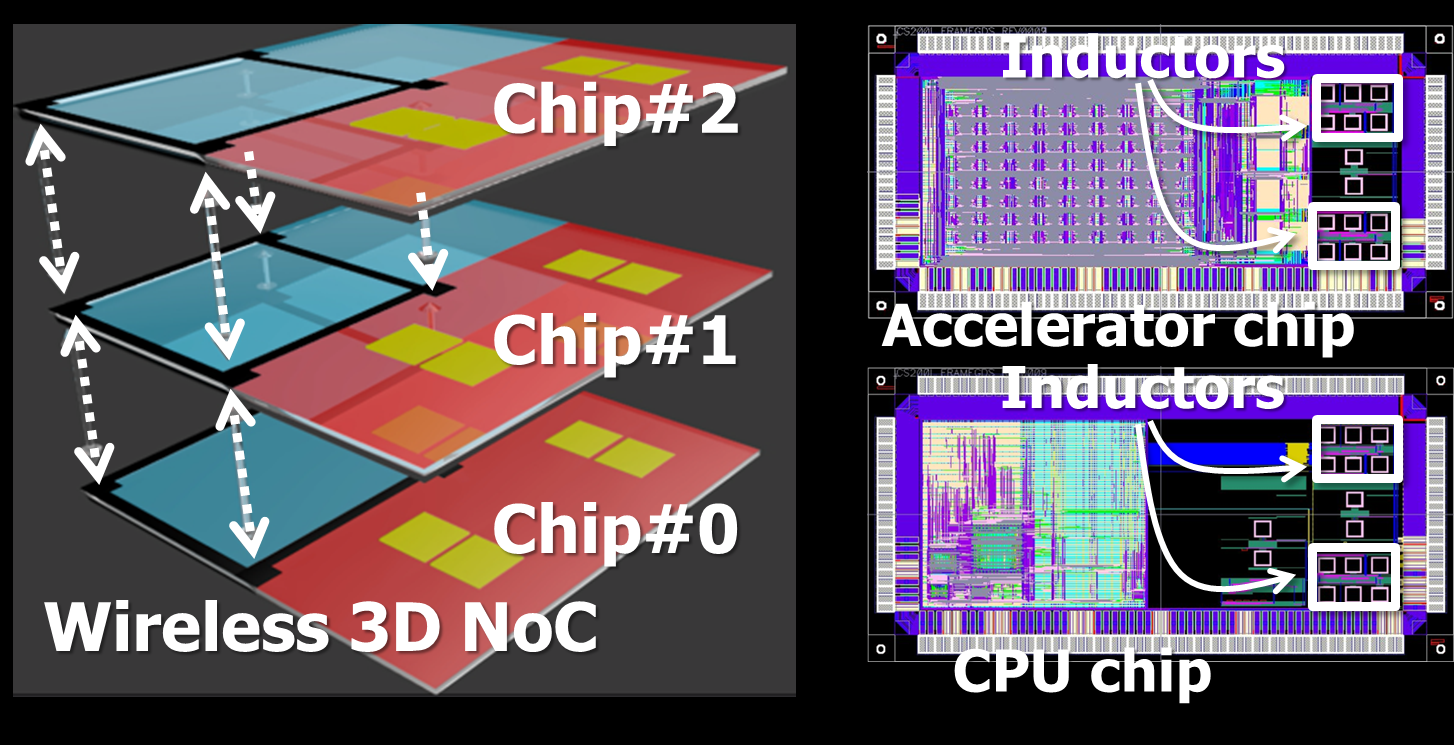
チップ間無線を用いた3次元メニーコアプロセッサ(2009年〜2019年)
パソコンCPUでもマルチコアが当たり前です。数十個から数百個のプロセッサコアが集積されたチップも開発されていて、これらは「メニーコアプロセッサ」と呼ばれます。このようなメニーコアはNetwork-on-Chip(NoC)と呼ばれるネットワークでつながります。松谷研では、このようなメニーコアチップを垂直方向に積層することを研究しました。
特にユニークなのが「ワイヤレス3次元NoC」の研究です(下図)。チップ内の水平ネットワークは通常のメタル配線を用いますが、チップ間の垂直ネットワークには慶應義塾大学電子工学科黒田研究室で開発された無線技術を用います。チップ間の接続が非接触の「ワイヤレス」であるという特徴を活かし、後からチップを入れ替え可能な計算機を研究しました。
※本研究は、情報工学科天野研究室と共同で進めました。2014年くらいまで米国のカーネギーメロン大学、南カリフォルニア大学と共同研究を行いました。