Welcome to Matsutani Lab @ Dept of ICS, Keio University, Japan
Research
Our research topics broadly cover computing infrastructures of various types and scales ranging from edge to cloud computing. Currently, we are working on on-device AI (Artificial Intelligence) and their implementations on resource-limited edge devices, highly-efficient distributed machine learning between edge and cloud, and in-network computing using network-attached FPGAs (Field-Programmable Gate Arrays) and GPUs (Graphics Processing Units). Below are some selected research topics.
- Lightweight on-device finetuning for DNN/CNN models
- On-device learning for field-trainable anomaly detection
- Highly-efficient FPGA-based accelerators for robotics
- Highly-efficient FPGA-based CNN accelerators using Neural ODE
- Distributed machine learning for Beyond 5G era
- High-performance in-network machine learning
- Accelerating data processing frameworks
- Accelerating NoSQL data stores
- Data center network with light beam
- Wireless 3D Network-on-Chips for building-block 3D systems
Our publication list is here.
Lightweight on-device finetuning for DNN/CNN models (2023-present)
We are working on lightweight on-device finetuning methods of deep neural networks for IoT devices. Deep models have been widely used in image classification, language models, generative models, and so on. We are expecting that these models will also be used in resource-limited edge devices. To address the gap between a pretrained model and a deployed edge environment, we are working on various lightweight on-device finetuning methods. For instance, our DNN finetuning method is running on $15 single-board computers.

- Hiroki Matsutani, et al., “Skip2-LoRA: A Lightweight On-device DNN Fine-tuning Method for Low-cost Edge Devices”, ASP-DAC’25, Jan 2025. [Paper]
- Keisuke Sugiura, et al., “InstantFT: A Field-Programmable Gate Array-Based Runtime Subsecond Fine-Tuning of Convolutional Neural Network Models”, IEEE Micro, May/Jun 2026. [Paper]
- Keisuke Sugiura, et al., “ElasticZO: A Memory-Efficient On-Device Learning with Combined Zeroth- and First-Order Optimization”, arXiv:2501.04287, Jan 2025. [Paper]
On-device learning for field-trainable anomaly detection (2017-present)
Toward on-device learning, we are working on a neural-network based online sequential learning and field-trainable anomaly detection algorithm and its related technologies. In real environments, noise pattern (e.g., vibration) fluctuates and status of products/tools varies with time. Our approach learns normal patterns including noises in a placed environment extemporarily to detect unusual ones, so no prior training is needed. It can train neural networks on $4 controllers.
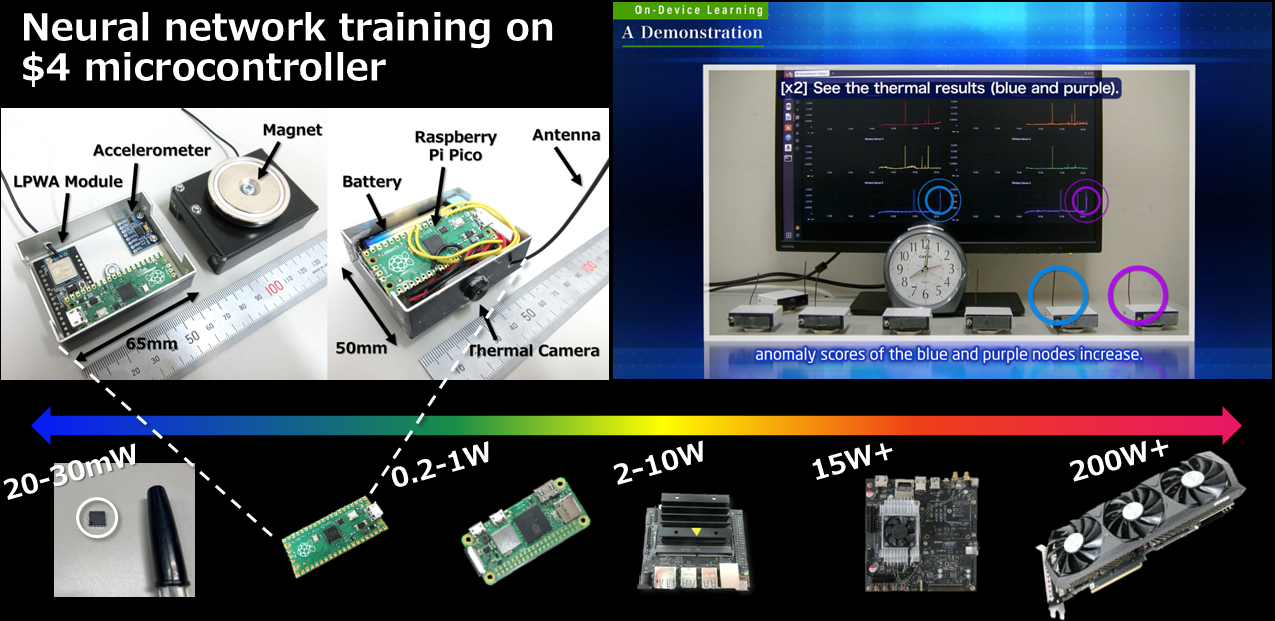
Below is an introduction of the on-device learning. Details are explained at tinyML.
- Kazuki Sunaga, et al., “Addressing Gap between Training Data and Deployed Environment by On-Device Learning”, IEEE Micro, Nov/Dec 2023. [Paper]
- Mineto Tsukada, et al., “A Neural Network Based On-device Learning Anomaly Detector for Edge Devices”, IEEE Trans. on Computers, Jul 2020. (Featured Paper in July 2020) [Paper]
- Rei Ito, et al., “An On-Device Federated Learning Approach for Cooperative Model Update between Edge Devices”, IEEE Access, Jun 2021. [Paper]
- Hirohisa Watanabe, et al., “An FPGA-Based On-Device Reinforcement Learning Approach using Online Sequential Learning”, IEEE IPDPS’21 Workshops (RAW’21), May 2021. [Paper]
Highly-efficient FPGA-based accelerators for robotics (2019-present)
We are working on highly-efficient LiDAR (Light Detection And Ranging) SLAM (Simultaneous Localization and Mapping) accelerators for mobile robots. As well-known 2D LiDAR SLAM methods, a particle filter based SLAM and a graph-based SLAM are accelerated by a low-cost PYNQ FPGA board as shown in the video below.
We are also working on highly-efficient FPGA-based accelerators for point cloud registration and 2D/3D path planning. Below is a demonstration of the deep learning based point cloud registration on FPGA.
- Keisuke Sugiura, et al., “A Universal LiDAR SLAM Accelerator System on Low-cost FPGA”, IEEE Access, Mar 2022. [Paper]
- Keisuke Sugiura, et al., “An Integrated FPGA Accelerator for Deep Learning-based 2D/3D Path Planning”, IEEE Trans. on Computers, Jun 2024. (Featured Paper in June 2024) [Paper]
- Keisuke Sugiura, et al., “FPGA-Accelerated Correspondence-free Point Cloud Registration with PointNet Features”, ACM Trans. on Reconfigurable Technology and Systems, May 2025. [Paper]
Highly-efficient FPGA-based CNN accelerators using Neural ODE (2020-present)
We are working on highly-efficient Convolutional Neural Network (CNN) inference accelerators for edge devices. Specifically, ordinary differential equation (ODE) based neural networks (Neural ODEs) are implemented on low-cost FPGA devices. It is combined with Depthwise separable convolution (DSC) to further reduce parameter size.
Currently, we are combining Neural ODE and multi-head self-attention mechanism for CNN-Transformer hybrid tiny model. Below is a demo video of the tiny model on a modest sized FPGA.
- Ikumi Okubo, et al., “A Cost-Efficient FPGA-Based CNN-Transformer using Neural ODE”, IEEE Access, Oct 2024. [Paper]
- Hiroki Kawakami, et al., “A Low-Cost Neural ODE with Depthwise Separable Convolution for Edge Domain Adaptation on FPGAs”, IEICE Trans. on Information and Systems, Jul 2023. [Paper]
- Hirohisa Watanabe, et al., “Accelerating ODE-Based Neural Networks on Low-Cost FPGAs”, IEEE IPDPS’21 Workshops (RAW’21), May 2021. [Paper]
Distributed machine learning for Beyond 5G era (2021-present)
We are working on networked AI systems for Beyond 5G era, such as those for distributed deep learning, distributed deep reinforcement learning, and federated learning. For instance, we are proposing network optimizations for distributed deep reinforcement learning systems where actors are working at edge side while a learner is in cloud side.
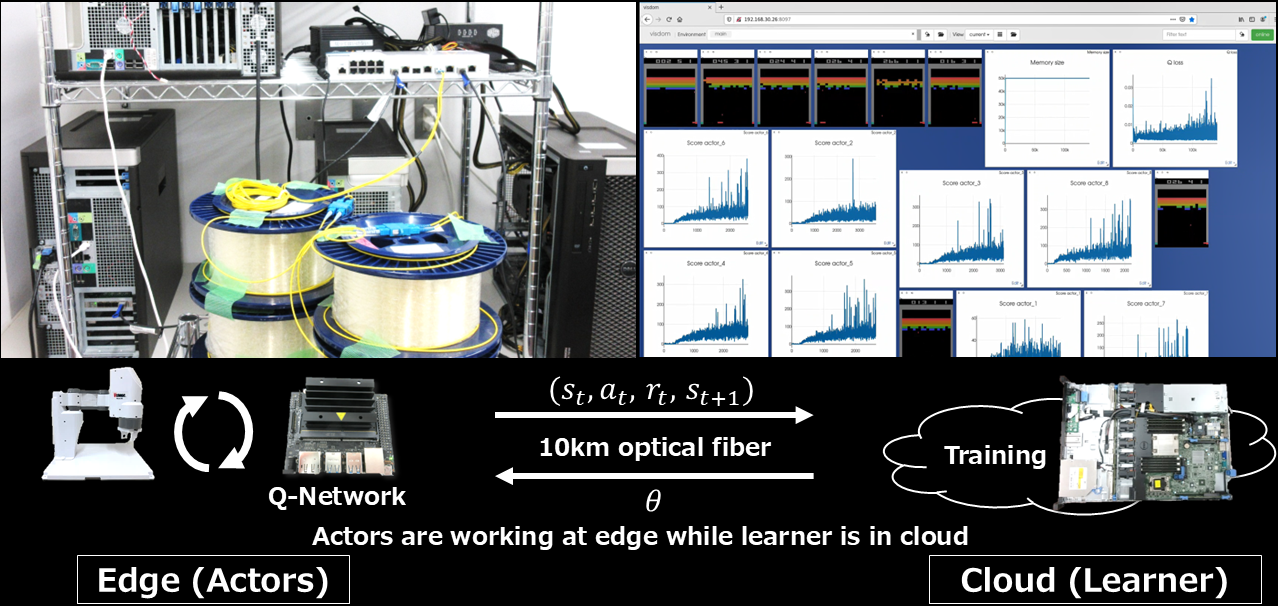
We are also working on acceleration of federated learning using Smart NICs.
- Masaki Furukawa, et al., “Accelerating Distributed Deep Reinforcement Learning by In-Network Experience Sampling”, PDP’22, Mar 2022. [Paper]
- Shin Morishima, et al., “An Efficient Distributed Reinforcement Learning Architecture for Long-haul Communication between Actors and Learner”, IEEE Access, May 2024. [Paper]
- Naoki Shibahara, et al., “Performance Improvement of Federated Learning Server using Smart NIC”, CANDAR’23 Workshops, Nov 2023. [Paper]
High-performance in-network machine learning (2014-2021)
We worked on machine learning for high-bandwidth network traffic using FPGA-based high-speed network interface cards (network-attached FPGAs) for outlier detection (k-nearest neighbor, local outlier factor), change-point detection (SDAR), and anomaly behavior detection (online HMM). We also proposed an in-network acceleration of optimization algorithms (SGD, AdaGrad, Adam, and SMORMS3) for distributed deep learning by using a 10Gbps FPGA-based network switch.
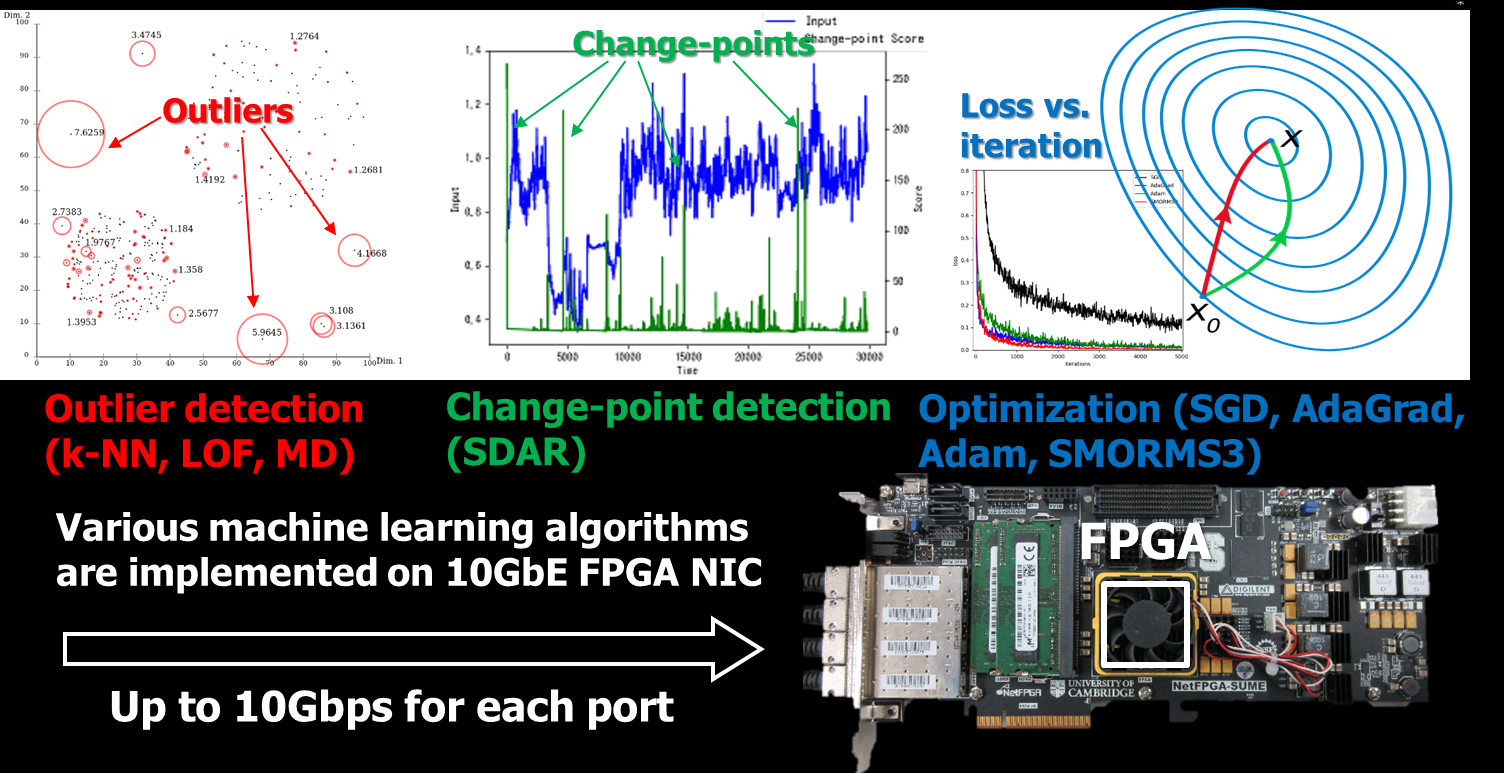
- Ami Hayashi, et al., “An FPGA-Based In-NIC Cache Approach for Lazy Learning Outlier Filtering”, PDP’17, Mar 2017. [Paper]
- Takuma Iwata, et al., “An FPGA-Based Change-Point Detection for 10Gbps Packet Stream”, IEICE Trans. on Information and Systems, Dec 2019. [Paper]
- Tomoya Itsubo, et al., “An FPGA-Based Optimizer Design for Distributed Deep Learning with Multiple GPUs”, IEICE Trans. on Information and Systems, Dec 2021. [Paper]
Accelerating data processing frameworks (2014-2019)
Big data processing system typically consists of various software components, such as message queuing, RPC, stream processing, batch processing, machine learning framework, and data stores. We proposed their performance acceleration methods by using network-attached FPGAs and network-attached GPUs.
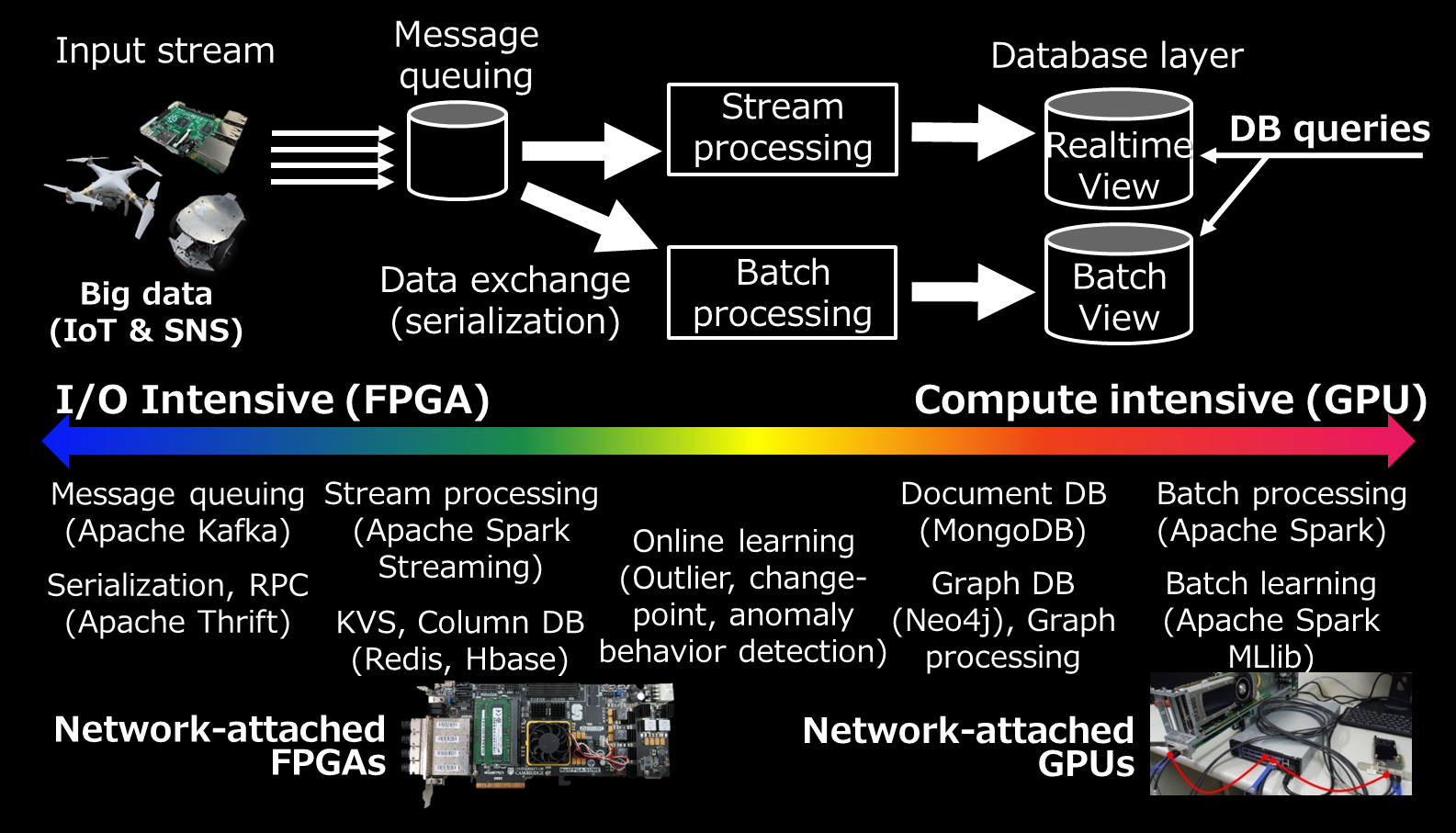
Apache Spark was accelerated by network-attached GPUs via 10Gbit Ethernet. RDDs were cached in device memory of these remote GPUs as shown in the video below.
- Yasuhiro Ohno, et al., “Accelerating Spark RDD Operations with Local and Remote GPU Devices”, IEEE ICPADS’16, Dec 2016. [Paper]
We also worked on rack-scale architecture using the network-attached FPGAs and GPUs. A remote GPU connected via 10Gbit Ethernet is pooled and used for virtual reality applications on demand as shown in the video below.
Accelerating NoSQL data stores (2013-2019)
We proposed performance acceleration methods of various NoSQLs including key-value store, column-oriented store, document-oriented store, and graph-oriented store by using network-attached FPGAs and network-attached GPUs. We also worked on acceleration of bitcoin/blockchain search. For instance, a key-value store was accelerated by a network-attached FPGA via 10Gbit Ethernet as shown in the video below.
- Yuta Tokusashi, et al., “Multilevel NoSQL Cache Combining In-NIC and In-Kernel Approaches”, IEEE Micro, Sep/Oct 2017. [Paper]
- Shin Morishima, et al., “High-Performance with an In-GPU Graph Database Cache”, IEEE IT Professional, Nov/Dec 2017. [Paper]
- Shin Morishima, et al., “Accelerating Blockchain Search of Full Nodes Using GPUs”, PDP’18, Mar 2018. [Paper]
Data center network with light beam (2012-2018)
A 40Gbps free-space optical link (light beam) was established between two computers and then virtual machine (VM) migration was performed using this “VM highway” as shown in the video below.
- Ikki Fujiwara, et al., “Augmenting Low-latency HPC Network with Free-space Optical Links”, IEEE HPCA’15, Feb 2015. [Paper]
Wireless 3D Network-on-Chips for building-block 3D systems (2009-2019)
We proposed inductive-coupling based wireless 3D Network-on-Chips for building-block 3D systems in which each chip or component can be added, removed, and swapped. Our “field-stackable” concept was demonstrated in Cube-0, Cube-1, and Cube-2 systems in which the numbers of CPU chips and accelerator chips can be customized.
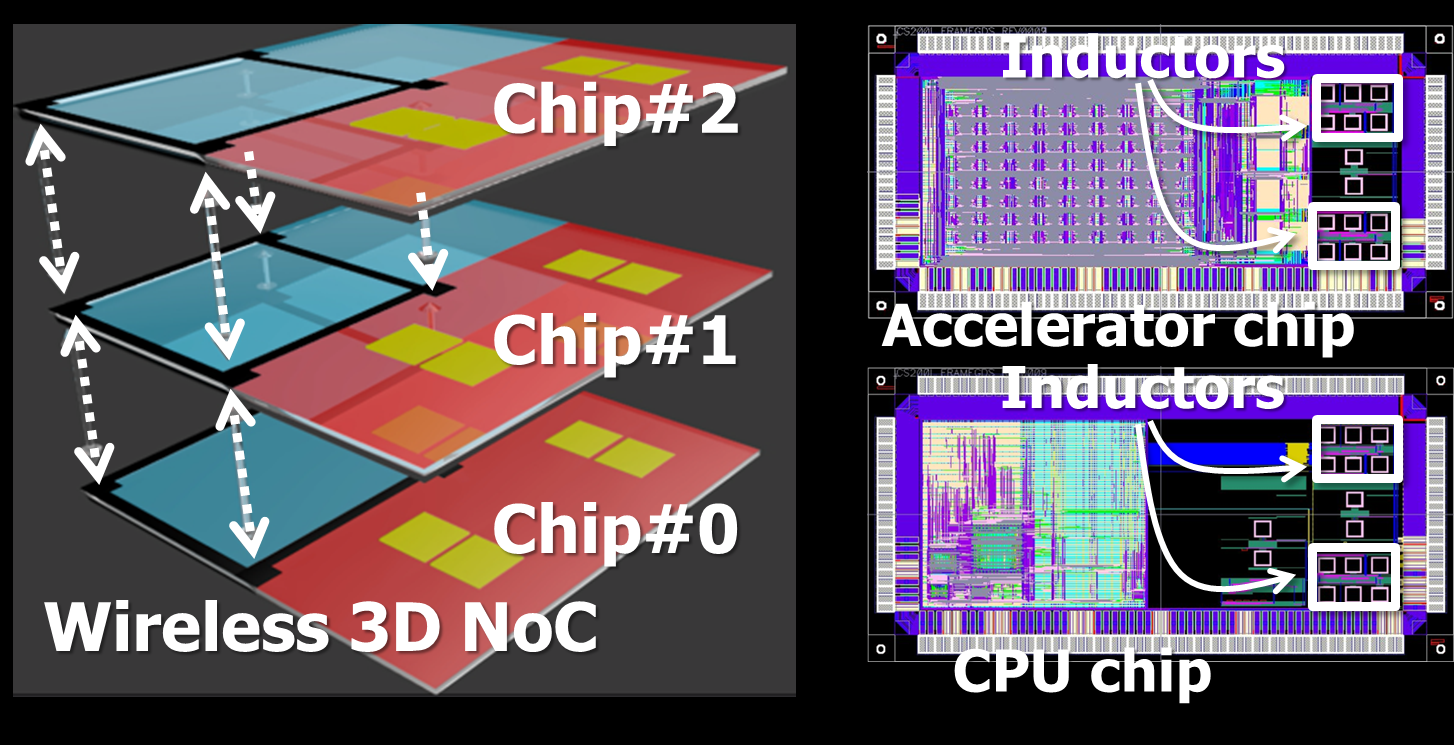
- Hiroki Matsutani, “A Building Block 3D System with Inductive-Coupling Through Chip Interfaces”, IEEE VTS’18, Special Session, Apr 2018. [Slide]
- Noriyuki Miura, et al., “A Scalable 3D Heterogeneous Multicore with an Inductive ThruChip Interface”, IEEE Micro, Nov/Dec 2013. [Paper]
Our NoC (Network-on-Chip) generator that generates Verilog HDL model of NoC consisting of on-chip routers, called nocgen, is available at GitHub.
Address
Department of Information and Computer Science, Keio University
3-14-1 Hiyoshi, Kouhoku-ku, Yokohama, JAPAN 223-8522
Laboratory
Rooms 26-207 and 26-210A at Yagami Campus
Access


Members
Professor
Ph.D. Course Student
- Naoto Sugiura
- Takenori Murata
2nd-Year Master Course Students
- Syuri Ijiri
- Shunsuke Inoue
- Shutaro Ota
- Hayato Sekine
- Quentin Morris
1st-Year Master Course Students
- Yuki Uno
- Naoki Matsuda
- Hilel Lazzoun
4th-Year Bachelor Course Students
- Takeru Ishii
- Kuga Masahiro
- Toshitsugu Kuwana
- Takumi Kojima
- Shintaro Sone
- Saaya Yamada